langdev
LangDev Meetup at CWI 8-9 March 2018
LangDev is generously sponsored by Itemis
![]()
Schedule
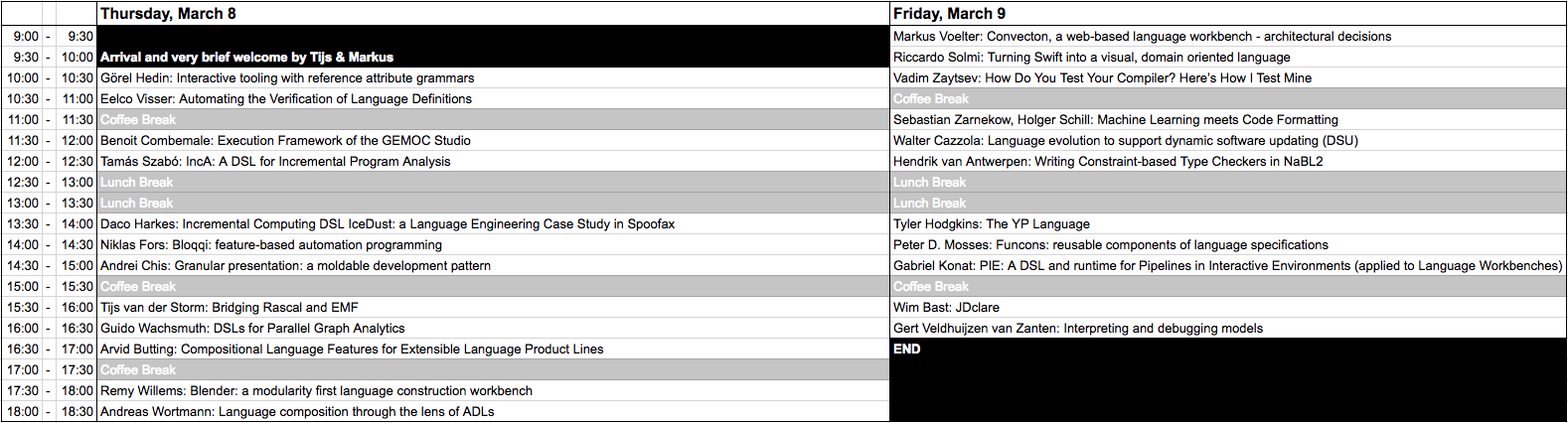
No Schedule change.
Talks and abstracts
Tijs van der Storm: Bridging Rascal and EMF slides
Code: https://github.com/cwi-swat/rascal-ecore
Rascal is based on functional programming, leveraging immutable tree structures described using algebraic data types. EMF on the other is based on class-oriented meta models, featuring bidirectional navigation and in-place update. In this demonstration we demonstrate how we have integrated both worlds, opening up the EMF eco system to Rascal, and vice versa. The interesting aspect is the explicit representation of change by abstract deltas, which allow synchronization of (modeling) artifacts across technical boundaries.
Markus Voelter: Convecton, a web-based language workbench - architectural decisions slides
Convecton is a language workbench we are currently building at itemis. It will run in the browser/cloud, and focus on domain experts as opposed to programmers. In this talk, I will illustrate how the requirements to be suitable for end users drove product design and software architecture. I will also introduce some aspects of our meta languages.
Eelco Visser: Automating the Verification of Language Definitions
Language workbenches automate large parts of the implementation of software languages. The next challenge in language workbenches is to automate the verification of properties of language definitions. For example, type soundness verification ensures that programs that pass the type checker do not go wrong at run-time. In this talk I discuss the progress we have made towards this goal in the Language Designer’s Workbench project. In particular, I will talk about the meta-languages we have developed for name and type analysis based on scope graphs and for dynamic semantics based on frames, and the techniques we have developed for proving interpreters sound by construction.
Niklas Fors: Bloqqi: feature-based automation programming slides
Bloqqi is a data-flow language designed for automation programming with focus on variability. The language supports object-orientation with diagram inheritance and diagram specialization with block redeclaration and connection interception. These constructs are the basis for the feature-based mechanisms supported in Bloqqi, where a base diagram can have optional- and alternative features. When a diagram with features is instantiated, an automatically derived wizard is shown where features can be selected. Feature libraries can be created and extended modularly. The compiler and the graphical editor for Bloqqi have been implemented using reference attribute grammar.
Tamás Szabó: IncA: A DSL for Incremental Program Analysis slides
Program analyses detect errors in code but have to trade off precision, recall, and performance. However, when code changes frequently as in an IDE, repeated re-analysis from-scratch is unnecessary and leads to poor performance. Incremental program analysis promises to deliver fast feedback after a code change by deriving a new analysis result from the previous one, and prior work has shown that order-of-magnitude performance improvements are possible. However, existing frameworks for incremental program analysis only support Datalog-style relational analysis, but not lattice-based analyses that derive and aggregate lattice values. To solve this problem, we present the IncAL incremental program analysis framework that supports relational analyses and lattice-based computations. IncAL is based on a novel algorithm that enables the incremental maintenance of recursive lattice-value aggregation, which occurs when analyzing looping code by fixpoint iteration. We realized strong-update points-to analysis and string analyses for Java in IncAL and present performance measurements that demonstrate incremental analysis updates within milliseconds.
Görel Hedin: Interactive tooling with reference attribute grammars slides
In past and ongoing projects, we are using reference attribute grammars to support interactive language tooling. The key advantage of this technique is to be able to program context-dependent editing and visualization in a modular and declarative way, and not having to worry about updating state. I will give an overview of the underlying technology, show example demos, and discuss prospectives for further development.
Gabriel Konat: PIE: A DSL and runtime for Pipelines in Interactive Environments (applied to Language Workbenches) slides
Language workbenches are complex pieces of software that compose different tasks into an interactive pipeline. They compile language specifications written in high-level meta-languages into efficient language implementations; perform language processing tasks such as parsing, analysis, and transformation; and integrate with interactive editor services of IDEs and code editors. However, language workbenches pipelines are implemented in ad-hoc ways, causing several problems. Their implementation is spread over different formalisms, resulting in increased development and maintenance effort. They lack dependency tracking, resulting in language developers having to manually stage compilation tasks. Furthermore, they lack properties such as incrementality, concurrency, and persistence, resulting in higher latencies. Finally, these properties may be unsound, resulting in users distrusting the pipeline. We have developed a solution to these problem with PIE: a DSL and runtime for programming interactive software development pipelines. With PIE, a pipeline developer can program their pipeline in a single high-level language without having to consider the incrementality, concurrency, and persistence properties of their pipeline. The PIE runtime incrementally executes these pipelines, has support for concurrency, and persists the result of a pipeline for restartability, while guaranteeing that these executions are sound with respect to from-scratch batch executions. We have applied PIE to the Spoofax language workbench by re-writing part of its pipeline in PIE. This prototype supports incremental language development where changes to a language specification result in updated feedback in the IDE. We hope that PIE can be useful to other pipeline developers, and are open to discuss problems, opportunities, and applications.
Hendrik van Antwerpen: Writing Constraint-based Type Checkers in NaBL2
Constraint systems are an established approach to specifying and implementing type checkers. Many proposed constraint systems focus on supporting challenging type system features. However, one aspect that has not received much attention is dealing with name resolution. Many approaches stick to lexical scoping during constraint generation, or rely on auxiliary mechanisms outside of the constraint language. We have proposed a constraint language that has support for rich binding structures at its core. The semantics and resolution of name binding is based on scope graphs – a language-independent theory of name resolution. Integrating name resolution in the constraint languages makes it possible to treat different binding patterns more uniformly. We can model lexical scoping, modules and imports, as well as type-dependent features such as record field access. NaBL2 is a meta-language, integrated in the Spoofax language workbench, that is based on this constraint language. NaBL2 allows the specification of type checkers by writing syntax-directed constraint generation rules. Specifications are turned into executable type checkers with the use of the accompanying constraint solver. In this demo, we want to show how different name binding and type system rules can be modeled in NaBL2, and pay special attention to cases where names and types interact. We hope to discuss possible applications, as well as future directions in constraint features and language design.
Peter D. Mosses: Funcons: reusable components of language specifications slides
In our component-based framework for language specification, the semantics of each language construct is defined by translation to a collection of pre-defined fundamental programming constructs (so-called ‘funcons’). This can be significantly easier than defining the semantics of language constructs directly, and might even encourage language developers to exploit formal semantics to document design decisions. We illustrate the approach and its tool support. </Abstract>
Gert Veldhuijzen van Zanten: Interpreting and debugging models slides
The advantages of business-level DSLs are greatly enhanced if the IDE s help the user to understand of the meaning of the sentences in the model. Interpretation and debugging facilities in an IDE can provide the necessary feedback
Andrei Chis: Granular presentation: a moldable development pattern
While developers express software using programming languages, they craft software exclusively by interacting with development tools. Unfortunately, all too often, when interacting with object-oriented applications developers rely on rigid development tools, focused only on object-oriented language constructs, unaware of the application domains under development. One approach for solving this is empowering developers to shape their development tools together with their domain models. Nonetheless, development tools are often hard to adapt or offer only shallow customisations. To investigate ways to reduce the effort for creating deep adaptations for development tools we propose the granular presentation pattern: allow objects to define presentations capturing domain-specific views and interactions using composable operators, and design development tools that leverage these presentations whenever interacting with an object. In this demo we will exemplify this pattern by lively introducing domain-specific adaptations into the inspector, the debugger and the editor to helps us better work with an existing application. The demo is based on the Glamorous Toolkit, the moldable IDE of the Pharo programming language.
Riccardo Solmi: Turning Swift into a visual, domain oriented language slides
Swift is a modern general purpose language with a grammar based textual notation. We propose a live experiment to make the Swift language as close as possible to the visual dsls available in the Whole Platform. Different flavors of the same language will help us discuss about some controversial choices in language design.
Tyler Hodgkins: The YP Language slides
Workday is an enterprise software company providing services to a variety of corporations, including Netflix, Visa, Sony, and Amazon. From its inception, Workday has relied on domain-specific languages (DSLs) to prototype and deliver accurate & comprehensive user experiences. Our developers build HR, Payroll, Finance and Student Services products using our XpressO language (XO).
XO is a functional reflective language that has served a decade as the foundation for a collection of interdependent domain-specific languages. These DSLs target specific problem spaces we encounter on a regular basis: custom UIs and & interaction, reporting, web services/APIs and business processes, to name a few. As we reach 7000 employees and beyond, problems have arisen due to the gradual design of these languages
The YP project, a new language and IDE for Workday developers, aims to solve these problems and prepare for a much broader scope of development. In this talk, I will discuss some of the specific problems we have faced with XpressO and the solutions we have included in our new YP IDE, along with how we will support internal and external development from the same environment.
Arvid Butting: Compositional Language Features for Extensible Language Product Lines
Modeling languages abstract from concrete problems and therefore reduce the gap between problem domain and solution. Different domains often encompass similar problems, which thereby share common modeling language concepts. To prevent re-engineering of these common concepts and to reduce the effort in creating, maintaining, and evolving these, language product lines capture common language concepts in language features. Language features enable reusing (parts of a) language in different contexts. We propose an approach for designing and implementing self-contained language features that can be developed independently by software language engineers. Further, our approach uses feature diagrams referencing language features for describing language product lines and includes a composition operator for language features that is used to automatically derive language variants. The mechanism produces language-processing tooling for each derived language variant on a push-button basis.
Sebastian Zarnekow, Holger Schill: Machine Learning meets Code Formatting slides
Automated code formatting is not a trivial problem. Formatting always has been a matter of taste, and it always will need a great deal of configuration switches to befriend all users. This is the reason why professional formatting tools, such as Eclipse or IDEA, offer a gazillion number of options. The downside is, that the formatter itself becomes increasingly more complex with each new available flag and in the end people still tend to format the code manually. Can’t we do better than that? What if we could use machine learning techniques to detect the preferred code style that was use in a codebase so far? Turns out, we can. The Antlr Codebuff project (https://github.com/antlr/codebuff) offers a generic formatter for pretty much any given language. As long as a grammar file exists, existing source can be analyzed to learn about the rules that have been applied while writing the code. Those can than be used to pretty print newly written code. No configuration required. And existing sources will stay as nicely formatted as they are. In the end, the primary purpose of code formatting is not to re-arrange all the keywords, but to make the source layout consistent. In this talk, we will demonstrate the usage of the codebuff project and how it can be used to format the sources of your repo in a consistent way. We’ll also show some other gems that have been revealed when toying around with the technology.
Remy Willems: Miksilo: a modularity first language construction workbench
We present Miksilo, a language construction workbench that places modularity first. Miksilo encapsulates language transformations to make them re-usable. Such transformations can both extend and contract a language, enabling transformations between arbitrary languages. We give a demo of a whole language transformation defined in Miksilo, and explore what makes this possible. Grammars in Miksilo are first class objects, allowing them to be easily manipulated. Parsed values are bound to fields early, enabling safely removing and adding parts of a grammar. Compiler phases are defined generically, allowing the AST’s structure to change without breaking the phase.
Andreas Wortmann: Language composition through the lens of ADLs
Modeling software systems as component & connector architectures with application-specific behavior modeling languages enables domain experts to describe each component behavior with the most appropriate language. Realizing the semantics of systems corresponding to such language aggregates requires composing the semantic mapping of the participating languages. We investigate how black-box code generator composition can facilitate deploying application-specific modeling language aggregates. Current work on code generator composition either focuses on white-box integration based on code generator internals or requires extensive handcrafting of integration code. We discuss an approach to black-box generator composition in the context of architecture description languages that relies on explicit generator interfaces and exploits the encapsulation of components. This approach is implemented for the architecture modeling infrastructure MontiArc and has been evaluated in various contexts. We present its details and discuss its generalizability towards other language aggregates. Highlights include the introduction to composition of concrete syntax, abstract syntax, and well-formedness rules with MontiCore, a demonstration that black-box generator composition works when restricting to various language kinds and an application to robotics
Vadim Zaytsev: How Do You Test Your Compiler? Here’s How I Test Mine slides
At Raincode Labs, we need test suites for our compilers for three different reasons: (1) to demonstrate the progress of language development to the customer, since we tend to have customers from day one who are very impatient and demanding; (2) to measure regression regularly and know well how the development is going in general; (3) to debug certain known or almost-known problems in the compiler, or to prep future features TDD-style.
Lacking the giant shoulders to stand on, we are coming up with our own solutions, which might be a good or a bad thing, and is commonly a mix of both. In one of the projects I am current working on, we ended up having more than a dozen of different kinds of tests: R-tests for testing if the parser can recognise a program text, P-tests that compare the tree structure produced by the parser, with an expected baseline, N-tests to see that normalisation, canonisation and desugaring works as expected, E-tests for seeing that erroneous situations get resolved in the desired way, T-tests to check that the symbol table contains expected identifiers with the right scopes and all properly typed, S-tests for something that can be parsed, normalised, typed, compiled, verified and executed to produce an a priori known outcome, X-tests that throw exceptions in response to unrecoverable errors, D-tests that access the runtime library functions directly… Each kind has between dozens and thousands of test cases. Of course, at certain maturity milestones larger integration-like tests start to become an option as well: compiling an entire MLOC-long portfolio; generating bind files for the database to connect to; even relying on human testers to see if the GUI elements are in the right places, if their colours look well and if clicking on buttons produces an expected response. I will bring a framework built from experience and desperation, and hope to collect buckets of valuable feedback on how to make the world a better place by properly testing our compilers.
Wim Bast: JDclare
Dclare is a declarative programming language. It is a multipurpose specification language that describes the world in with classes, properties, functions (without side-effects) and constraints. The constraints are automatically evaluated without any explicit specification of threads, observer-patterns, nor function composition. JDclare is a Java library to make declarative programs in Java, and to connect existing (imperative) Java libraries to be used declarative. We (the Modeling Value Group) are building a language-workbench using JDclare. DClare will also be the standard target language to reduce any declarative DSL to (like the ‘base-language’ in MPS or Xbase for Xtext). The Modeling Value Group has extensive experience in using different language-workbenches like Xtext, MPS and alike. We always need to develop our own libraries to build the different aspects of DSLs. (With aspects of DLSs we mean: syntax, scoping, type-checking, transformations, validation, debugging, explorers, tables, diagrams, etc.. This is because:
-
The workbenches for the build DSLs are not (out of the box) usable by non-technical users.
-
Most of the workbenches do not (or very poorly) support for immediate-feedback for typing, compiling, transforming, validations and alike.
-
The different meta-DSLs to define the different aspects of a DSL are not well (semantically) integrated (e.g. typing and scoping). * The meta-DSLs are not understandable without knowledge of the underlying imperative process.
-
You have to define a lot of extra (mostly redundant) code to make a workbench really usable.
-
The base-languages (like Xbase) are imperative languages, so that you have to reinvent the declarative aspect over and over again. Using DClare we solved many of the above issues. In fact, we use a DClare and EMF integration to solve several DSL aspects in our customer projects. However, we like to develop all aspects of the DSLs in DCLare (or meta DLSs on top of it) to have a better integrated solution. That is why we develop a new language workbench fully in DClare. The advantages of DClare are:
-
No monolithic elements (No threads, nor explicit function composition)
-
Common language concepts (Classes, Properties, Function, Constraints, Inheritance, Generics, Lambdas)
-
Instant consistency (No violation of any constraint guaranteed, exceptions if conflicting constraints exists) * Automatic and generic integration of all aspects.
-
Abstracts away from threads, events, observer-patterns, etc (essay to understand and maintain).
-
Instant immediate-feedback functionality We would like to share our experiences with building the language-workbench with you. We will talk about the different aspects of DSLs and the way they where specified using DClare. Some aspects became very essay to specify (typing, validation, gui, transformations), others are more challenging (like syntax parsing). The semantics of DClare will become clear based on the presented examples.
Guido Wachsmuth: DSLs for Parallel Graph Analytics
Demo of GreenMarl, a DSL to implement parallel graph algorithms, and PGQL, a SQL-like query language for graphs. Discuss integration into Oracle products, requiring different modi of language use
Daco Harkes: Incremental Computing DSL IceDust: a Language Engineering Case Study in Spoofax slides
IceDust is a domain-specific language for incremental computing of derived values in information systems. IceDust has been developed in the Spoofax language workbench over the last four years. In this talk we will highlight how some IceDust implementation details are expressed in Spoofax, how Spoofax’ features helped or slowed IceDust development, and how Spoofax’ evolution over the years shaped the IceDust implementation.
Walter Cazzola: Language evolution to support dynamic software updating (DSU)
Today software systems play a critical role in society’s infrastructures and many are required to provide uninterrupted services in their constantly changing environments. As the problem domain and the operational context of such software changes, the software itself must be updated accordingly. In this talk/demo we propose to support dynamic software updating through language semantic adaptation; this is done through use of micro-languages that confine the effect of the introduced change to specific application features. Micro-languages provide a logical layer over a programming language and associate an application feature with the portion of the programming language used to implement it. Thus, they permit to update the application feature by updating the underlying programming constructs without affecting the behaviour of the other application features. Such a linguistic approach provides the benefit of easy addition/removal of application features (with a special focus on non-functional features) to/from a running application by separating the implementation of the new feature from the original application, allowing for the application to remain unaware of any extensions. The feasibility of this approach is demonstrated with two studies; its benefits and drawbacks are also analysed.»
Benoit Combemale: Execution Framework of the GEMOC Studio
The development and evolution of an advanced IDE for a Domain-Specific Language (DSL) is a tedious task. Recent efforts in language workbenches result in frameworks that automatically provide syntactic tooling such as advanced editors. However, defining the execution semantics of languages and their tooling remains mostly hand crafted. Similarly to editors that share code completion or syntax highlighting, the development of advanced debuggers, animators, and others execution analysis tools shares common facilities, which should be reused among various DSLs. In this talk, I will present and make a demo of the execution framework offered by the GEMOC studio, an Eclipse-based language and modeling workbench. The framework provides a generic interface to plug in different execution engines associated to their specific metalanguages used to define the discrete-event operational semantics of DSMLs (e.g., Kermeta/Xtend, xMOF, ALE…). It also integrates generic runtime services that are shared among the approaches used to implement the execution semantics, such as graphical animation and omniscient debugging (provided by Sirius Animator).